强化学习算法的元学习框架
发布日期:2021-02-22 11:30:55 来源: 编辑:
当前的强化学习算法使用规则集进行工作,根据该规则集,通过观察当前环境状态来不断更新代理的参数。提高这些算法效率的一种可能方法是使用自动从可用数据中发现更新规则,同时使算法适应特定的环境条件。这个研究方向仍然提出了很多挑战。
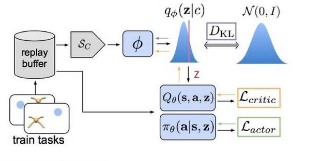
在arXiv.org上发表的最新论文中,作者提议创建元学习平台,该平台可以发现整个更新规则,包括预测目标(或值函数)以及通过与一组环境交互从中学习的方法。在他们的实验中,研究人员使用一组三个不同的元训练环境来尝试元学习完整的强化学习更新规则,从而证明了这种方法的可行性以及其自动化和加速新机器学习算法发现的潜力。
本文首次尝试通过共同发现“预测内容”和“如何进行引导”来元学习完整的RL更新规则,从而取代了现有的RL概念(例如价值函数和TD学习)。一小组玩具环境的结果表明,发现的LPG可以在预测中保留丰富的信息,这对于有效的引导非常重要。我们认为,这只是完全数据驱动的RL算法发现的开始;从我们的程序生成环境到新的高级体系结构和替代的产生经验的方法,有许多很有希望的方向来扩展我们的工作。从玩具领域到Atari游戏的彻底概括表明,从与环境的互动中发现有效的RL算法可能是可行的,
标签: 强化学习算法