描述单个机器学习模型决策的框架
现代机器学习模型,例如神经网络,通常被称为“黑匣子”,因为它们非常复杂,以至于即使是设计它们的研究人员也无法完全理解它们是如何做出预测的。
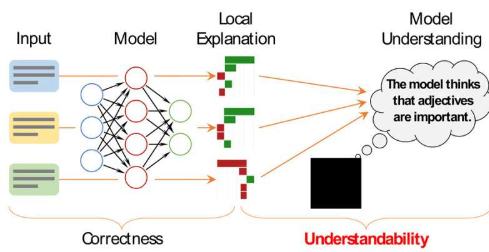
为了提供一些见解,研究人员使用试图描述单个模型决策的解释方法。例如,他们可能会在电影评论中突出显示影响模型决定评论是正面的单词。
但是,如果人类不能轻易理解,甚至误解它们,这些解释方法就没有任何用处。因此,麻省理工学院的研究人员创建了一个数学框架来正式量化和评估机器学习模型解释的可理解性。如果研究人员仅评估少数个别解释以尝试理解整个模型,这有助于查明可能遗漏的模型行为见解。
“有了这个框架,我们不仅可以非常清楚地了解我们从这些本地解释中对模型的了解,更重要的是,我们不了解它,”电气工程和计算机科学专业的毕业生Yilun Zhou 说计算机科学和人工智能实验室 (CSAIL) 的学生,也是介绍该框架的论文的主要作者。
周的合著者包括微软研究院高级研究员 Marco Tulio Ribeiro 和高级作者、航空航天学教授、CSAIL 交互式机器人组主任 Julie Shah。该研究将在计算语言学协会北美分会会议上发表。
了解当地的解释
理解机器学习模型的一种方法是找到另一个模仿其预测但使用透明推理模式的模型。然而,最近的神经网络模型非常复杂,以至于这种技术通常会失败。相反,研究人员求助于使用关注个人输入的本地解释。通常,这些解释会突出显示文本中的单词,以表明它们对模型做出的一个预测的重要性。
然后,人们隐含地将这些局部解释推广到整体模型行为。有人可能会看到,当模型确定电影评论具有积极情绪时,局部解释方法突出显示积极词(如“难忘”、“完美无瑕”或“迷人”)是最有影响力的。然后他们可能会假设所有积极的词都会对模型的预测做出积极的贡献,但情况可能并非总是如此,周说。
研究人员开发了一个框架,称为 ExSum(解释摘要的缩写),将这些类型的声明形式化为可以使用可量化指标进行测试的规则。ExSum 评估整个数据集上的规则,而不仅仅是为其构造的单个实例。
使用图形用户界面,个人编写可以调整、调整和评估的规则。例如,当研究一个学习将电影评论分类为正面或负面的模型时,人们可能会写一条规则说“否定词具有负面显着性”,这意味着像“不”、“不”和“无”这样的词对电影评论的情绪产生负面影响。
使用 ExSum,用户可以使用三个特定指标查看该规则是否成立:覆盖率、有效性和清晰度。覆盖率衡量规则在整个数据集中的适用范围。有效性突出显示符合规则的单个示例的百分比。清晰度描述了规则的精确程度;一个高度有效的规则可能非常通用,以至于对理解模型没有用处。
测试假设
如果研究人员想要更深入地了解她的模型的行为方式,她可以使用 ExSum 来测试特定的假设,Zhou 说。
如果她怀疑她的模型在性别方面具有歧视性,她可以制定规则说男性代词有正贡献,女性代词有负贡献。如果这些规则具有很高的有效性,则意味着它们总体上是正确的,并且模型可能存在偏差。
ExSum 还可以揭示有关模型行为的意外信息。例如,在评估电影评论分类器时,研究人员惊讶地发现,与正面词相比,负面词往往对模型的决策有更尖锐和更尖锐的贡献。周解释说,这可能是由于评论作家在批评电影时试图保持礼貌而不那么直率。
“要真正确认你的理解,你需要在很多情况下更严格地评估这些说法。据我们所知,这种细粒度级别的理解在以前的作品中从未发现过,”他说。
“从本地解释到全球理解是文献中的一个巨大差距。ExSum 是填补这一差距的良好第一步,”Ribeiro 补充道。
扩展框架
在未来,周希望通过将可理解性的概念扩展到其他标准和解释形式,如反事实解释(表明如何修改输入以改变模型预测)来建立这项工作。目前,他们专注于特征归因方法,这些方法描述了模型用于做出决策的各个特征(如电影评论中的文字)。
此外,他希望进一步增强框架和用户界面,以便人们可以更快地创建规则。编写规则可能需要数小时的人工参与——而某种程度的人工参与至关重要,因为人类最终必须能够掌握解释——但人工智能的帮助可以简化这一过程。
在思考 ExSum 的未来时,周希望他们的工作强调需要改变研究人员对机器学习模型解释的看法。
“在这项工作之前,如果你有一个正确的本地解释,你就完成了。你已经达到了解释你的模型的圣杯。我们提出了这个额外的维度来确保这些解释是可以理解的。可理解性需要成为评估的另一个指标我们的解释,”周说。
标签: