研究人员提出了新的更有效的自动语音识别模型
Siri和AmazonAlexa等流行的语音助手已经向更广泛的公众推出了自动语音识别(ASR)。尽管已有数十年的历史,但ASR模型仍难以保持一致性和可靠性,尤其是在嘈杂的环境中。中国研究人员开发了一种框架,可有效提高ASR针对日常声学环境混乱的性能。
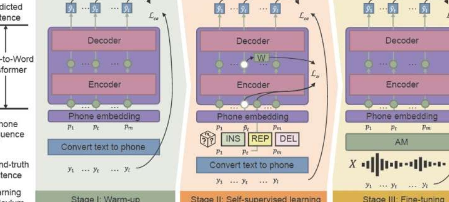
香港科技大学和微众银行的研究人员提出了一个新的框架——语音语义预训练(PSP),并展示了他们的新模型对合成高噪声语音数据集的鲁棒性。
他们的研究于8月28日发表在CAAI人工智能研究上。
“鲁棒性是ASR长期面临的挑战,”香港科技大学计算机科学与工程系的XueyangWu说。“我们希望以低成本提高中国ASR系统的稳健性。”
ASR使用机器学习和其他人工智能技术将语音自动翻译成文本,用于语音激活系统和转录软件等用途。但新的以消费者为中心的应用程序越来越多地要求语音识别更好地工作——处理更多的语言和口音,并在视频会议和现场采访等现实生活中更可靠地执行。
传统上,训练包含ASR的声学和语言模型需要大量特定于噪声的数据,这可能会耗费时间和成本。
声学模型(AM)将单词变成“音素”,它们是基本声音的序列。语言模型(LM)将音素解码为自然语言句子,通常有两个步骤:一个快速但相对较弱的LM生成一组候选句子,而一个强大但计算量大的LM从候选句子中选择最佳句子。
“传统的学习模型对嘈杂的声学模型输出并不稳健,尤其是对于具有相同发音的中文和弦词,”吴说。“如果第一遍学习模型解码不正确,第二遍就很难弥补。”
新提出的框架PSP可以更容易地恢复错误分类的单词。通过预训练将AM输出与完整上下文信息一起直接转换为句子的模型,研究人员可以帮助LM从AM的嘈杂输出中有效地恢复。
PSP框架允许模型通过称为噪声感知课程的预训练机制进行改进,该机制逐渐引入新技能,从简单开始并逐渐转向更复杂的任务。
“我们提出的方法中最关键的部分,即噪声感知课程学习,模拟了人类如何从嘈杂的语音中识别句子的机制,”吴说。
预热是第一阶段,研究人员在干净的音素序列上预训练音素转换器,该音素序列仅从未标记的文本数据转换而来,以减少注释时间。这个阶段“预热”模型,初始化基本参数以将音素序列映射到单词。
在第二阶段,自我监督学习中,传感器从自我监督训练技术和功能生成的更复杂的数据中学习。最后,生成的语音到单词转换器使用真实世界的语音数据进行微调。
研究人员通过实验证明了他们的框架在从工业场景和合成噪声中收集的两个真实数据集上的有效性。结果表明,PSP框架有效地改进了传统的ASR流水线,将第一个数据集的相对字符错误率降低了28.63%,第二个数据集降低了26.38%。
在接下来的步骤中,研究人员将使用更大的未配对数据集研究更有效的PSP预训练方法,以最大限度地提高抗噪LM预训练的有效性。
标签: