研究人员开发了用于自动驾驶的AI模型
由博士OskarNatan组成的研究小组。丰桥工业大学计算机科学工程系主动智能系统实验室(AISL)的学生和他的导师JunMiura教授开发了一种可以同时处理自动驾驶感知和控制的AI模型车辆。
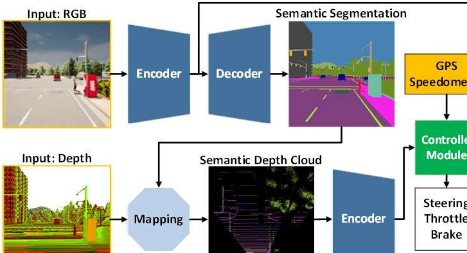
AI模型通过完成多个视觉任务来感知环境,同时驾驶车辆沿着一系列路线点行驶。此外,人工智能模型可以在各种场景下的各种环境条件下安全驾驶车辆。在点对点导航任务下进行评估,人工智能模型在标准模拟环境中实现了某些最新模型的最佳驾驶性能。
自动驾驶是一个复杂的系统,由多个处理多个感知和控制任务的子系统组成。然而,部署多个特定于任务的模块成本高且效率低,因为仍然需要大量配置来形成集成的模块化系统。
此外,集成过程可能会导致信息丢失,因为许多参数是手动调整的。通过快速的深度学习研究,可以通过训练具有端到端和多任务方式的单个AI模型来解决这个问题。因此,该模型可以仅基于一组传感器提供的观察来提供导航控制。由于不再需要手动配置,模型可以自行管理信息。
端到端模型面临的挑战是如何提取有用信息,以便控制器能够正确估计导航控制。这可以通过向感知模块提供大量数据以更好地感知周围环境来解决。此外,传感器融合技术可用于增强性能,因为它融合了不同的传感器以捕获各种数据方面。
然而,巨大的计算负载是不可避免的,因为需要更大的模型来处理更多的数据。此外,数据预处理技术是必要的,因为不同的传感器通常带有不同的数据模式。此外,训练过程中的不平衡学习可能是另一个问题,因为模型同时执行感知和控制任务。
为了应对这些挑战,该团队提出了一种经过端到端和多任务方式训练的AI模型。该模型由两个主要模块组成,即感知模块和控制器模块。感知阶段首先处理由单个RGBD相机提供的RGB图像和深度图。
然后,控制器模块对从感知模块提取的信息以及车辆速度测量和路线点坐标进行解码,以估计导航控制。为了确保所有任务都能平等执行,该团队采用了一种称为修正梯度归一化(MGN)的算法来平衡训练过程中的学习信号。
该团队考虑模仿学习,因为它允许模型从大规模数据集中学习以匹配接近人类的标准。此外,该团队将模型设计为使用比其他模型更少的参数来减少计算负载并加速在资源有限的设备上的推理。
根据标准自动驾驶模拟器CARLA的实验结果,表明融合RGB图像和深度图以形成鸟瞰(BEV)语义图可以提高整体性能。由于感知模块对场景有更好的整体理解,控制器模块可以利用有用的信息来正确估计导航控制。此外,该团队表示,所提出的模型更适合部署,因为与其他模型相比,它以更少的参数实现了更好的驾驶性能。
该研究发表在IEEETransactionsonIntelligentVehicles上,该团队目前正在对模型进行修改和改进,以解决在夜间、大雨等光照条件差的情况下驾驶时的几个问题。假设,该团队认为添加不受亮度或照度变化影响的传感器,例如LiDAR,将提高模型的场景理解能力并带来更好的驾驶性能。另一个未来的任务是将提出的模型应用于现实世界中的自动驾驶。
标签: